
Дата публикации:Thu, 08 Jan 2026 09:18:00 +0300
Опубликованы результаты исследования времени обнаружения и устранения ошибок в коде ядра Linux. Данные получены в результате анализа исправления 125 тысяч ошибок, помеченных в Git-репозитории тегом "Fixes:", ссылающимся на коммит, в котором возникла ошибка. Среднее время обнаружения ошибок в ядре составило 2.1 года. Если рассматривать только ошибки, исправленные в 2025 году, данный показатель составил 2.8 года.
30% ошибок были исправлены теми же разработчиками, что и внесли ошибки. 56.9% ошибок устраняют в течение года. 13.5% ошибок оставались незамеченными более 5 лет (если рассматривать только ошибки, исправленные в 2025 году - 19.4%). Из-за неравномерности распределения медианное время существования ошибки в коде ядра составило 8 месяцев для выборки с 2005 года и 1 год для ошибок, исправленных в 2025 году. Наиболее долго сохранявшейся в коде ошибкой стало переполнение буфера в ethtool, устранённое спустя 20.7 лет.
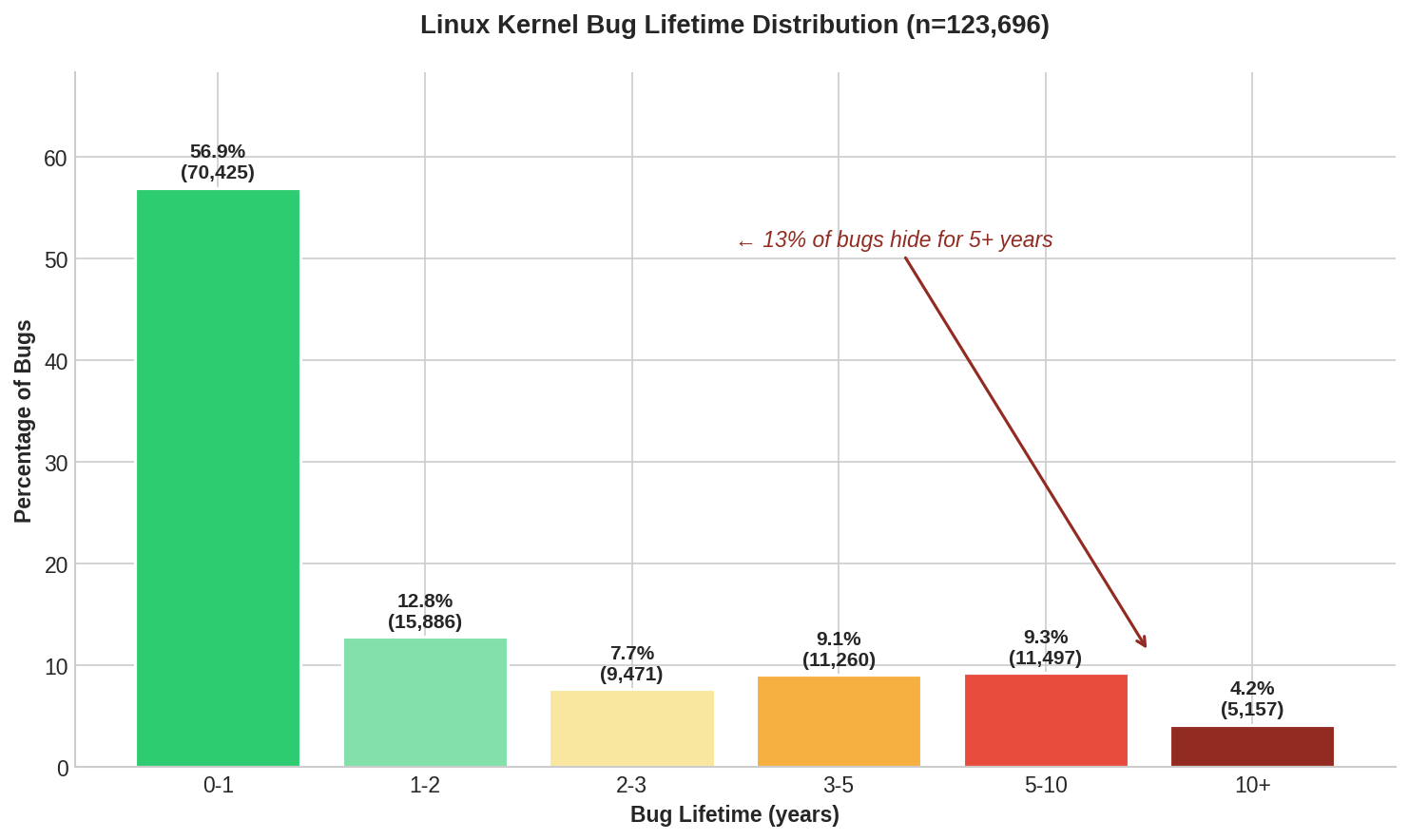
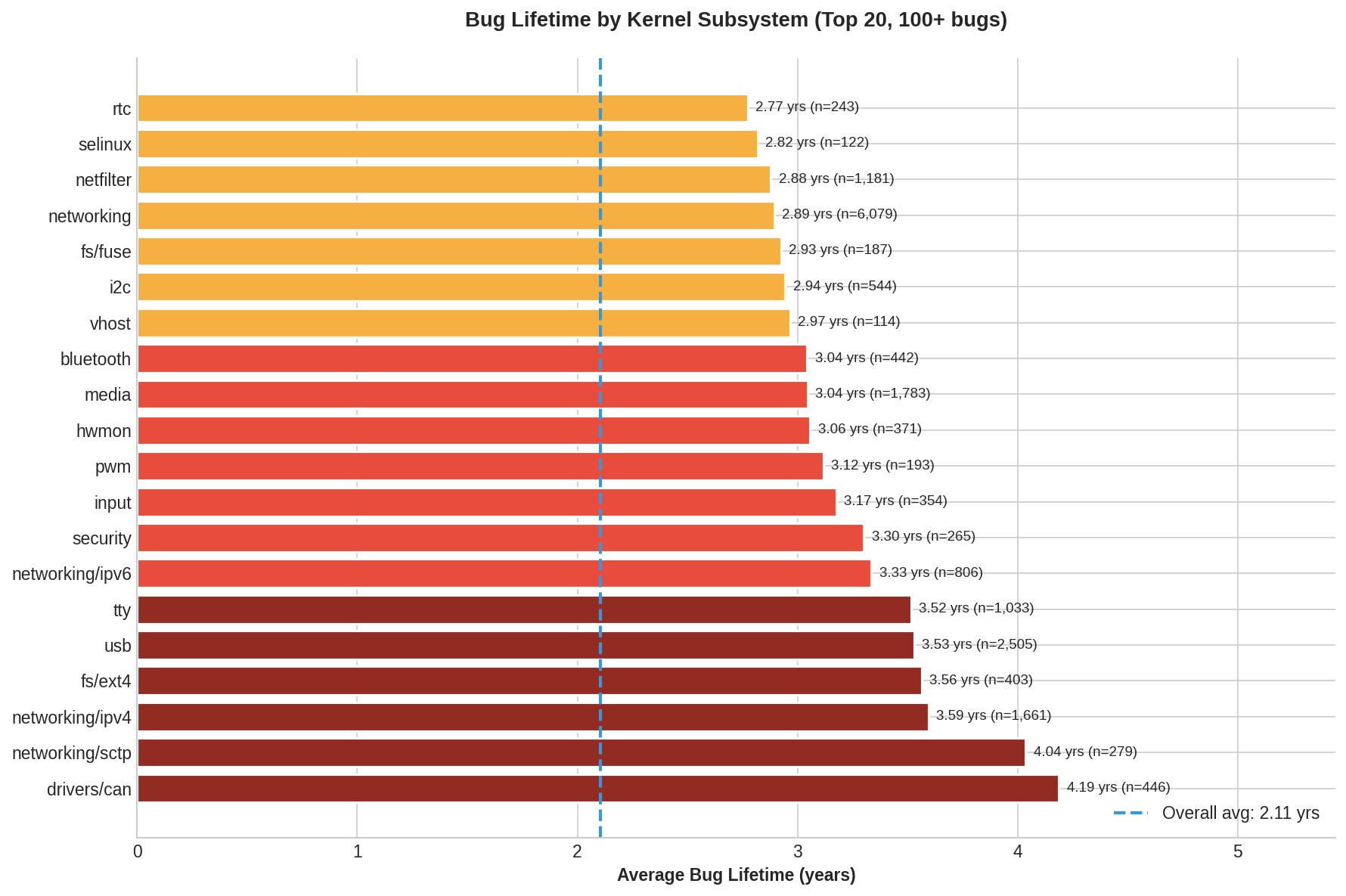
В полученной статистике также прослеживается влияние внедрения новых инструментов для автоматизированного поиска ошибок, статического анализа и тестирования кода, таких как Syzkaller, KASAN, KMSAN и KCSAN. Например, в 2010 году не было зафиксировано исправлений ошибок, найденных в течение года. В то время, как в 2014 году в течение года выявлялось 31% ошибок, 2018 году - 54%, а в 2022 году - 69% ошибок.
Полученная статистика была использована для создания модели машинного обучения VulnBERT, позволяющей предсказывать наличие уязвимостей в коммитах. При тестировании на коммитах за 2024 год точность обнаружения ошибок составила 92.2% при уровне ложных срабатываний 1.2% (для сравнения ранее доступная модель CodeBERT выявляла 89.2% проблем при уровне ложного срабатывания 48.1%).
Новость позаимствована с opennet.ru
Ссылка на оригинал: https://www.opennet.ru/opennews/art.shtml?num=64574