
Дата публикации:Tue, 02 Apr 2024 19:44:07 +0300
Компания Databricks объявила об
открытии большой языковой модели DBRX, которая может применяться для создания чатботов, отвечающих на вопросы на естественном языке, решающих предложенные математические задачи, способных генерировать контент на заданную тему и создавать код на различных языках программирования. Модель разработана компанией Mosaic ML, которая была куплена Databricks за 1.3 млрд долларов. Для обучения использовался кластер из 3072 GPU NVIDIA H100 Tensor Core. Для запуска готовой модели рекомендуется 320GB памяти.
При обучении модели применялась архитектура MoE (Mixture of experts), позволяющая получить более точную экспертную оценку, и коллекция текстов и кода, размером 12 Tb. Размер учитываемого моделью DBRX контекста составляет 32 тысяч токенов (число токенов, которые модель может обработать и запомнить при генерации текста). Для сравнения размер контекста у моделей Google Gemini и OpenAI GPT-4 составляет 32 тысячи токенов, Google Gemma - 8 тысяч, а у модели GPT-4 Turbo - 128 тысяч.
Модель охватывает 132 миллиарда параметров и разделена на 16 экспертных сетей, из которых при обработке запроса могут использоваться не более 4 (охват не более 36 млрд параметров для каждого токена). Для сравнения модель GPT-4 предположительно включает 1.76 триллиона параметров, недавно открытая X/Twitter модель Grok (X/Twitter) - 314 млрд, GPT-3.5 - 175 млрд, YaLM (Yandex) - 100 млрд, LLaMA (Meta) - 65 млрд, GigaChat (Sber) - 29 млрд, Gemma (Google) - 7 млрд.
Модель и связанные с ней компоненты распространяются под лицензией Databricks Open Model License, позволяющей использовать, воспроизводить, копировать, изменять и создавать производные продукты, но с некоторыми ограничениями. Например, лицензия запрещает использовать DBRX, производные модели и любой вывод на их основе для улучшения других языковых моделей, отличных от DBRX. Лицензия также запрещает использовать модель в областях, нарушающих законы и нормативные акты.
Производные модели должны распространяться под той же лицензией. При использовании в продуктах и серивисах, которыми пользуются более 700 млн пользователей в месяц, требуется получение отдельного разрешения.
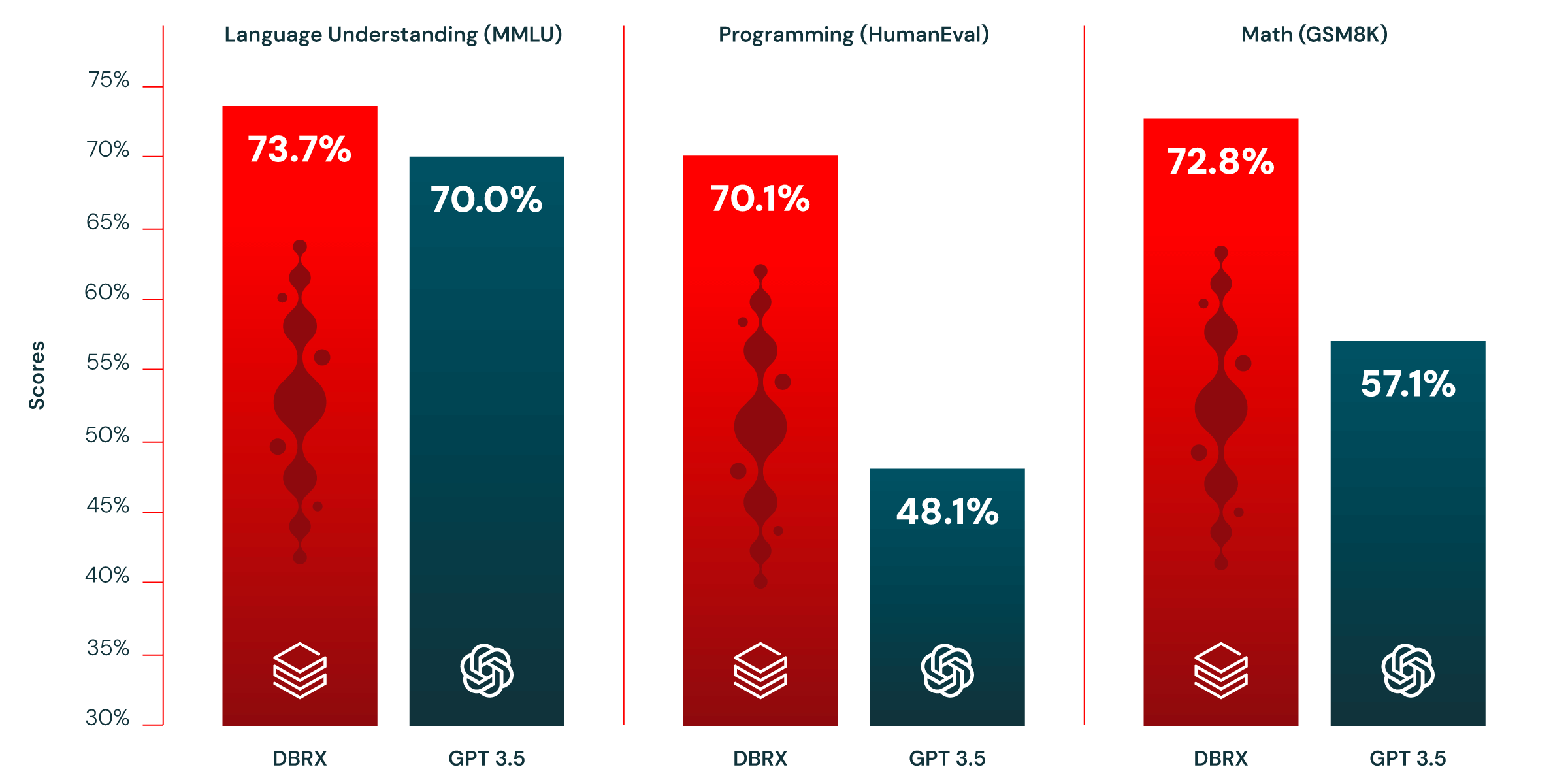
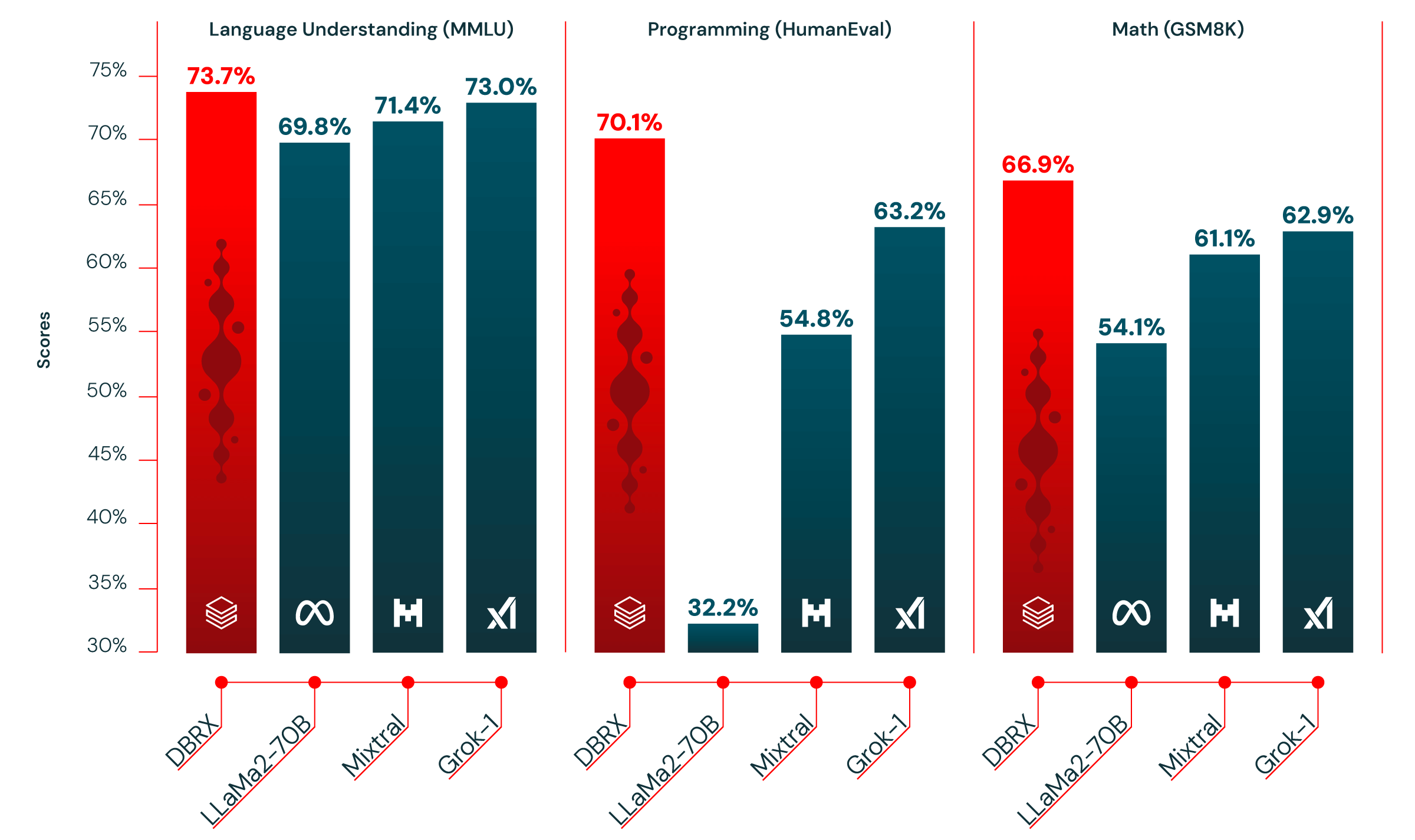
По заявлению создателей модели, по своим характеристикам и возможностям DBRX превосходит модели GPT-3.5 от компании OpenAI и Grok-1 от Twitter, и может конкурировать с моделью
Gemini 1.0 Pro при тестировании степени понимания языка, возможностям написания кода на языках программирования и решению математических задач. В некоторых применениях, например, при генерации SQL-запросов, DBRX приближается по эффективности к модели GPT-4 Turbo, которая лидирует на рынке. Кроме того, модель отличается от конкурирующих сервисов очень быстрой работой и позволяет формировать ответ почти мгновенно. В частности, DBRX может генерировать текст со скоростью до 150 токенов в секунду на одного пользователя, что примерно в два раза быстрее модели LLaMA2-70B.
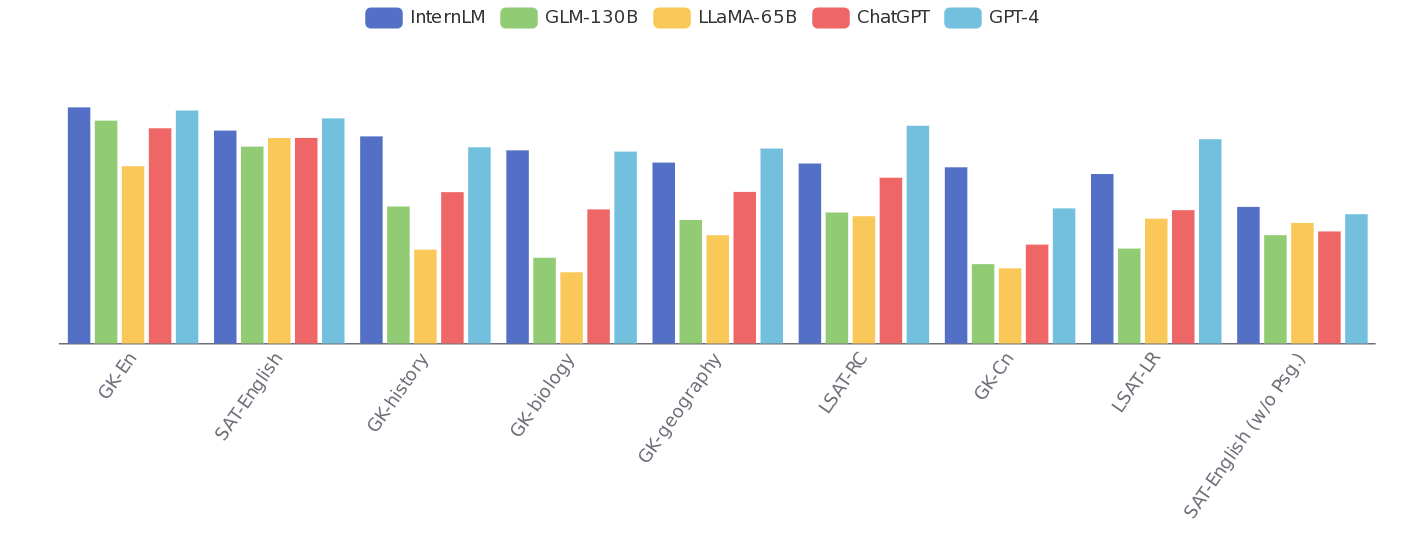
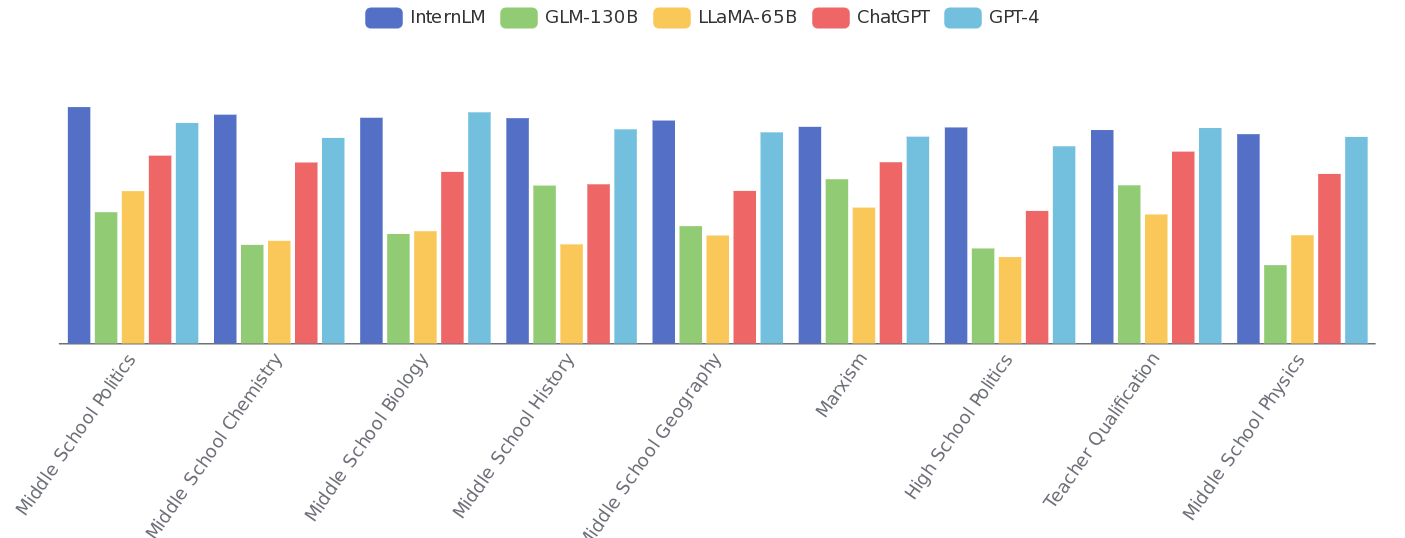
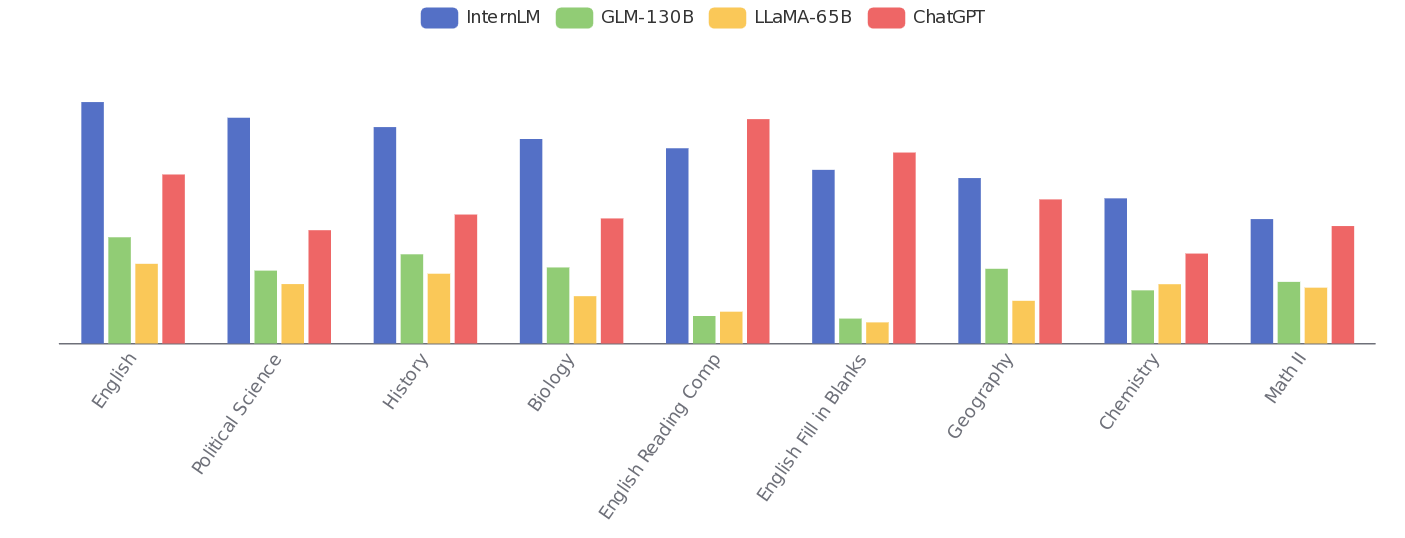
Дополнительно можно отметить публикацию технического описания открытой большой языковой модели InternLM2, которая распространяется под лицензией Apache 2.0, доступна в вариантах с 20, 7 и 1.8 миллиардами параметров. Модель развивается шанхайской лабораторией искусственного интеллекта при участии нескольких китайских университетов и примечательна учётом до 200K токенов контекста и поддержкой не только английского, но и китайского языка. Во многих тестах модель близка к GPT-4.
Кроме того, сообщается о разработке 84 новых ядра умножения матриц для инструментария llamafile, развиваемого Mozilla и позволяющего создавать универсальные исполняемые файлы для запуска больших языковых моделей машинного обучения (LLM). Изменения позволили значительно увеличить производительность работы моделей в llamafile пи выполнении на CPU. Например, по сравнению с инструментарием llama.cpp llamafile теперь быстрее от 30% до 500% в зависимости от окружения, а по сравнению с библиотекой
MKL матричные операции, которые умещаются в кэш L2, выполняются в два раза быстрее.
Новость позаимствована с opennet.ru
Ссылка на оригинал: https://www.opennet.ru/opennews/art.shtml?num=60911